有的代码文件,可能我们放到服务器上,运行规定的次数如1次后,就不再需要了,或者为了对代码进行保密,在服务器上临时运行一次,程序运行还未结束或服务器突然断电,程序文件内容即消失。
有两种方式,可以在执行程序开始,随着代码载入内存开始,对该代码文件实行文件销毁,或者对代码文件里内容进...
fireling
10年前 (2016-01-27) 9997℃ 0评论
5喜欢
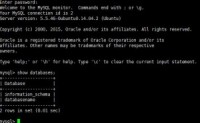
使用MySQL,可以在本地局域网测试,但很多情况下,我们需要通过给定的服务器及端口信息,来连接服务器上的数据库来进行操作。如何配置呢?
在服务器上安装好MySQL后,首先要启动mysqld服务。这样的话,我们可以使用安装时配置好的用户及密码,进行登录。默认情况下,服务器端上的M...
fireling
10年前 (2016-01-15) 18204℃ 0评论
16喜欢
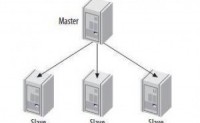
对于计算密集型任务来说,我们可以采用多进程或多线程方式进行操作,也可以采用多台机器进行并行计算,实现效率的大大提升,总得来说,精髓在于对于大数据的“分而治之”。
在分布式系统中,一个比较常用的计算结构就是Master/Slave模式。简单来说,Master/Slave与进程与线...
fireling
10年前 (2016-01-14) 21810℃ 0评论
28喜欢
大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的。你可以把它比作一个厨房所以需要的各种工具。锅碗瓢盆,各有各的用处,互相之间又有重合。你可以用汤锅直接当碗吃饭喝汤,你可以用小刀或者刨子去皮。但是每个工具有自己的特性,虽...
fireling
10年前 (2016-01-14) 7997℃ 0评论
6喜欢