对网易新闻排行榜的抓取,是我以前学爬虫做的一个小实验。像下图,我的目的就是想把网易新闻排行榜这个页面下的所有新闻的标题和对应的链接都下载下来,分专题保存。
抓取页面很容易,但是有一点,在页面分析的时候,我发现并不是所有专题的页面结构是一样的。用正则表达式分析的话,速度确实慢了点...
fireling
11年前 (2015-11-19) 42851℃ 0评论
258喜欢
Python入门网络爬虫之精华版
Python学习网络爬虫主要分3个大的版块:抓取,分析,存储
另外,比较常用的爬虫框架Scrapy,这里最后也详细介绍一下。
首先列举一下本人总结的相关文章,这些覆盖了入门网络爬虫需要的基本概念和技巧:宁哥的小站-网络爬虫
当我们在浏览器中...
fireling
11年前 (2015-08-19) 53986℃ 0评论
173喜欢
验证码是一种非常有效的反爬虫机制,它能阻止大部分的暴力抓取,在电商类、投票类以及社交类等网站上应用广泛。如果破解验证码,成为了数据抓取工作者必须要面对的问题。
在访问某些网站时,我们最初只是需要提供用户名密码就可以登陆的,比如说豆瓣网,如果我们要是频繁登陆访问,可能这时网站就会出...
fireling
11年前 (2015-08-05) 42562℃ 0评论
80喜欢
GitHub传送门
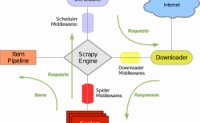
有很多开源的网络爬虫,如果我们掌握某一种或多种开源的爬虫工具,再我们获取数据的道路上会如虎添翼,事半功倍。这里我介绍一下我对于Scrapy网络爬虫的学习和搭建。
Scrapy使用了Twisted异步网络库来处理网络通讯。整体架构大致如下:
S...
fireling
11年前 (2015-06-26) 46507℃ 0评论
119喜欢
我们经常有这样的上网经历,就是如果你采用用户名密码登陆一个网站之后,如果在一段不长的时间内,再次访问这个本来需要你登陆的网站,你会很轻易地访问,而不需要再次输入用户名密码。这种“免登陆”的体验无疑给用户带来了非常好的体验,那为什么会“免登陆”呢?是什么在起作用呢?
答案就是Coo...
fireling
12年前 (2015-02-10) 22750℃ 0评论
26喜欢
POST请求比较常见的一种情况就是用户名密码登陆情况,这里介绍一种用程序登陆豆瓣账号的流程。
在豆瓣需要我们输入用户名密码,才能获得我们用户里面相关的数据。那么我们通过POST方式传给服务器的数据在哪里呢?与GET方式一样,我们可以在Chrome浏览器中查看请求头...
fireling
12年前 (2015-01-27) 80077℃ 0评论
19喜欢