HBase介绍
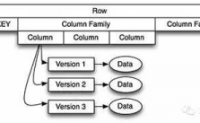
HBase是运行于HDFS顶层的非关系型数据库,它具备随即读写功能,是一种面向列的数据库。
我们都知道,Hive能将SQL指令转化为MapReduce任务执行,虽然它基于HDFS存储,但仍可看作分布式的SQL系统。与之相比,HBase采用了Bigtable的数据...
fireling
9年前 (2018-01-25) 14446℃
14喜欢
ZooKeeper是一个针对大型分布式系统的协作系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。ZooKeeper的角色,相当于整个Hadoop动物体系里面的动物管理员。我们在运行HBase时,需要先配备ZooKeeper。这里主要讲一下ZooKeeper的几种...
fireling
9年前 (2018-01-10) 14055℃
16喜欢
本文讲一下Hive对数据的导入导出操作,加深大家对Hive的认识和理解。
首先,创建t_hive.txt文件,作为原始数据,内容如下:
导入数据操作
从操作本地文件系统(LOCAL)导入数据
hive> create table t_hive (a int, b i...
fireling
9年前 (2017-12-08) 8475℃
7喜欢
Hive介绍
Hive是一个构建于Hadoop顶层的数据仓库。它依赖于HDFS和MapReduce,对HDFS数据提供类似于SQL的操作,可以将SQL语句转换为MapReduce任务进行运行。这样,Hive实现了以SQL查询方式来分析存储在HDFS中的数据,使得不熟悉MapRe...
fireling
9年前 (2017-11-29) 8018℃
4喜欢
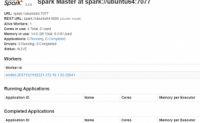
以前看过Hadoop及Spark的相关资料,最近又搭建了Hadoop及Spark集群,“反刍”了一下,发现目前的新版本与以前又有了一些变化。Hadoop目前发布了3版本,而Spark已经更新到了2.2版本。本文主要讲一下Spark的搭建及使用。
使用Spark会用到Hadoop...
fireling
9年前 (2017-11-21) 7896℃
1喜欢
搭建Spark运行环境:
可以自搭建Hadoop的standalone版,主要配置在于JDK和Hadooop的环境变量设置。
在此基础上搭建Spark的standalone版,下载“Hadoop Free”版本,主要配置在于Scala和Spark的环境变量设置。
如果使用到之...
fireling
10年前 (2016-05-24) 12574℃
9喜欢