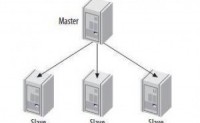
对于计算密集型任务来说,我们可以采用多进程或多线程方式进行操作,也可以采用多台机器进行并行计算,实现效率的大大提升,总得来说,精髓在于对于大数据的“分而治之”。
在分布式系统中,一个比较常用的计算结构就是Master/Slave模式。简单来说,Master/Slave与进程与线...
fireling
11年前 (2016-01-14) 22069℃ 0评论
28喜欢
大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的。你可以把它比作一个厨房所以需要的各种工具。锅碗瓢盆,各有各的用处,互相之间又有重合。你可以用汤锅直接当碗吃饭喝汤,你可以用小刀或者刨子去皮。但是每个工具有自己的特性,虽...
fireling
11年前 (2016-01-14) 8238℃ 0评论
6喜欢
云计算(Cloud Computing)
云计算这个名词来自于Google,而最早的云计算产品来自于Amazon。有意思的是,Google在2006年正式提出云计算这个名词的时候,Amazon的云计算产品AWS(Amazon Web Service)已经正式运作差不多4年了。因此...
fireling
11年前 (2015-09-11) 8407℃ 0评论
5喜欢