本文讲一下Hive对数据的导入导出操作,加深大家对Hive的认识和理解。
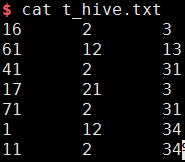
首先,创建t_hive.txt文件,作为原始数据,内容如下:
导入数据操作
从操作本地文件系统(LOCAL)导入数据
hive> create table t_hive (a int, b int, c int) row format delimited fields terminated by '\t';
hive> load data local inpath '/home/lining/t_hive.txt' overwrite into table t_hive;
hive> select * from t_hive;
查看结果:
16 2 3
61 12 13
41 2 31
17 21 3
71 2 31
1 12 34
11 2 34
从HDFS文件系统中查看导入的数据:
${HADOOP_HOME}/bin/hdfs dfs -cat /user/hive/warehouse/t_hive/t_hive.txt
查看结果:
16 2 3
61 12 13
41 2 31
17 21 3
71 2 31
1 12 34
11 2 34
从HDFS文件系统导入数据
hive> create table t_hive2 (a int, b int, c int) row format delimited fields terminated by '\t';
hive> load data inpath '/user/hive/warehouse/t_hive/t_hive.txt' overwrite into table t_hive2;
hive> select * from t_hive2;
查看结果:
OK
16 2 3
61 12 13
41 2 31
17 21 3
71 2 31
1 12 34
11 2 34
Time taken: 0.138 seconds, Fetched: 7 row(s)
从其他表导入数据
hive> create table t_hive3 (a int, b int, c int) row format delimited fields terminated by '\t';
hive> insert overwrite table t_hive3 select * from t_hive;
运行得到:
Query ID = lining_20171208112258_d422d070-04e1-4a5c-b48e-56b3abd6f71f
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1512702929231_0004, Tracking URL = http://ubuntu64:8088/proxy/application_1512702929231_0004/
Kill Command = /opt/hadoop/bin/hadoop job -kill job_1512702929231_0004
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2017-12-08 11:23:02,671 Stage-1 map = 0%, reduce = 0%
2017-12-08 11:23:06,823 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
MapReduce Total cumulative CPU time: 1 seconds 220 msec
Ended Job = job_1512702929231_0004
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to directory hdfs://localhost:9000/user/hive/warehouse/t_hive3/.hive-staging_hive_2017-12-08_11-22-58_361_150732114309606378-1/-ext-10000
Loading data to table default.t_hive3
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 1.22 sec HDFS Read: 3867 HDFS Write: 127 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 220 msec
OK
Time taken: 10.898 seconds
创建表并从其他表导入数据
hive> create table t_hive4 as select * from t_hive;
运行得到:
Query ID = lining_20171208112447_3e7dce46-06d3-4950-a58c-c6abaa529092
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1512702929231_0005, Tracking URL = http://ubuntu64:8088/proxy/application_1512702929231_0005/
Kill Command = /opt/hadoop/bin/hadoop job -kill job_1512702929231_0005
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2017-12-08 11:24:52,473 Stage-1 map = 0%, reduce = 0%
2017-12-08 11:24:56,637 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.27 sec
MapReduce Total cumulative CPU time: 1 seconds 270 msec
Ended Job = job_1512702929231_0005
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to directory hdfs://localhost:9000/user/hive/warehouse/.hive-staging_hive_2017-12-08_11-24-47_392_3653884924137606893-1/-ext-10002
Moving data to directory hdfs://localhost:9000/user/hive/warehouse/t_hive4
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 1.27 sec HDFS Read: 3550 HDFS Write: 127 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 270 msec
OK
Time taken: 10.987 seconds
创建表并从其他表导入表结构不导入数据
hive> create table t_hive5 like t_hive;
hive> select * from t_hive5;
查看结果:
OK
Time taken: 0.105 seconds
导出数据操作
从HDFS复制到HDFS其他位置
${HADOOP_HOME}/bin/hdfs dfs -cp /user/hive/warehouse/t_hive /
${HADOOP_HOME}/bin/hdfs dfs -ls /t_hive
${HADOOP_HOME}/bin/hdfs dfs -cat /t_hive/t_hive.txt
查看结果:
16 2 3
61 12 13
41 2 31
17 21 3
71 2 31
1 12 34
11 2 34
通过Hive导出到本地文件系统
hive> insert overwrite local directory '/home/lining/t_hive' select * from t_hive;
cat /home/lining/t_hive/000000_0
查看结果:
1623
611213
41231
17213
71231
11234
11234
转载请注明:宁哥的小站 » Hive对数据的导入导出介绍