计算机如何执行进程呢?这是计算机运行的核心问题。即使已经编写好程序,但程序是死的。只有活的进程才能产出。现在我们看一下从程序是如何执行进程的。
下面是一个简单的C程序,假设该程序已经编译好,生成可执行文件vamei.exe。
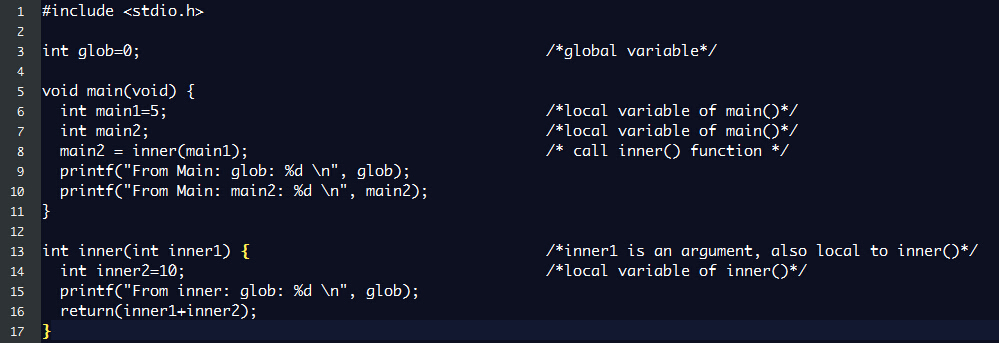
(选取哪一个语言或者具体的语法并不是关键,大部分语言都可以写出类似上面的程序。在看Python教程的读者也可以利用Python的函数结构和print写一个类似的python程序。当然,还可以是C++,Java,Objective-C等等。选用C语言的原因是:它是为UNIX而生的语言。)
main()函数中调用了inner()函数。inner()中调用一次printf()以输出。最后,在main()中进行了两次printf()。
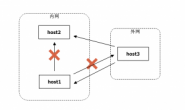
注意变量的作用范围。简单地说,变量可以分为全局变量和局部变量。在所有函数之外声明的变量为全局变量,比如glob,在任何时候都可以使用。在函数内定义的变量为局部变量,只能在该函数的作用域(range)内使用,比如说我们在inner()工作的时候不能使用main()函数中声明的main1变量,而在main()中我们无法使用inner()函数中声明的inner2变量。
不用太过在意这个程序的具体功能。要点是这个程序的运行过程。下图为该程序的运行过程,以及各个变量的作用范围:
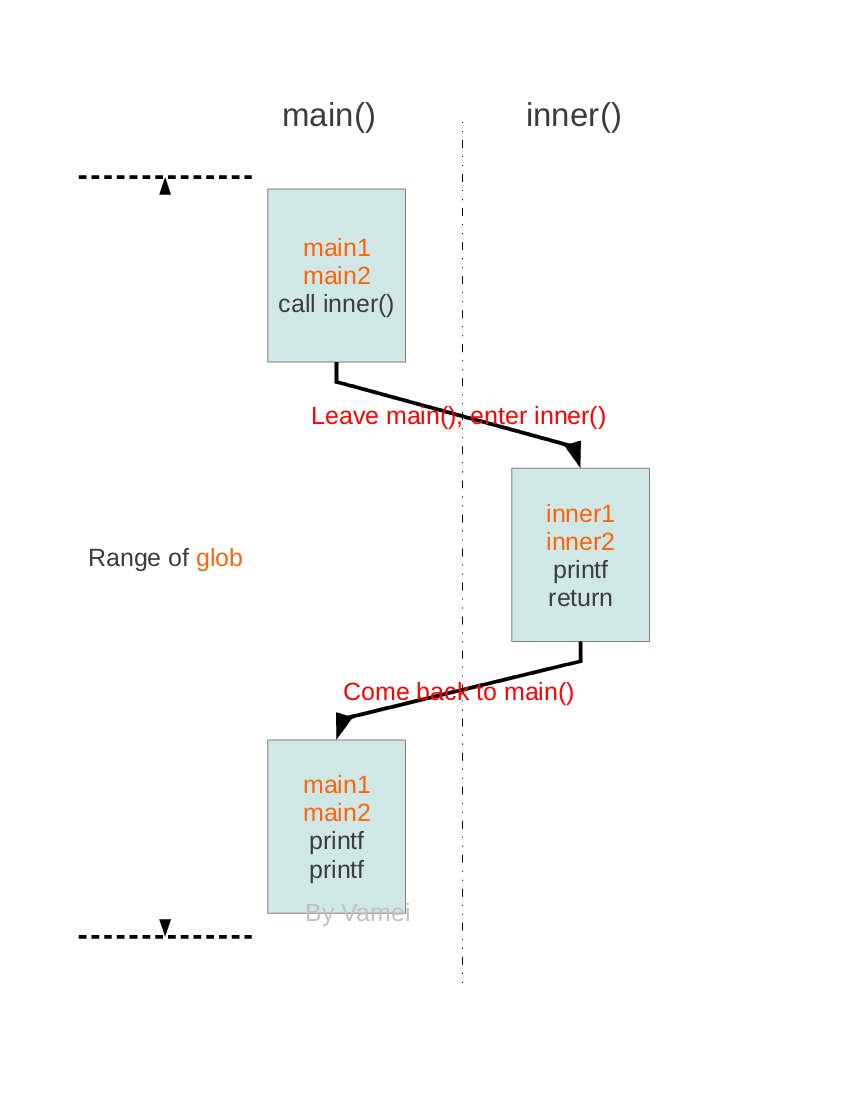
为了进一步了解上面程序的运行,我们还需要知道,进程如何使用内存。当程序文件运行为进程时,进程在内存中获得空间。这个空间是进程自己的小屋子。
每个进程空间按照如下方式分为不同区域:
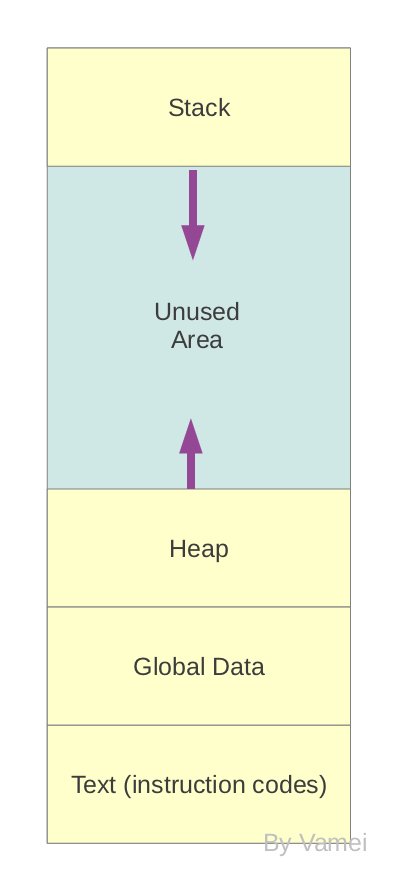
Text区域用来储存指令(instruction),说明每一步的操作。Global Data用于存放全局变量,栈(Stack)用于存放局部变量,堆(heap)用于存放动态变量 (dynamic variable.程序利用malloc系统调用,直接从内存中为dynamic variable开辟空间)。Text和Global data在进程一开始的时候就确定了,并在整个进程中保持固定大小。
栈(Stack)以帧(stack frame)为单位。当程序调用函数的时候,比如main()函数中调用inner()函数,stack会向下增长一帧。帧中存储该函数的参数和局部变量,以及该函数的返回地址(return address)。此时,计算机将控制权从main()转移到inner(),inner()函数处于激活(active)状态。位于栈最下方的帧,和全局变量一起,构成了当前的环境(context)。激活函数可以从环境中调用需要的变量。典型的编程语言都只允许你使用位于stack最下方的帧,而不允许你调用其它的帧(这也符合stack结构“先进后出”的特征。但也有一些语言允许你调用栈的其它部分,相当于允许你在运行inner()函数的时候调用main()中声明的局部变量,比如Pascal)。当函数又进一步调用另一个函数的时候,一个新的帧会继续增加到栈的下方,控制权转移到新的函数中。当激活函数返回的时候,会从栈中弹出(pop,读取并从栈中删除)该帧,并根据帧中记录的返回地址,将控制权交给返回地址所指向的指令(比如从inner()函数中返回,继续执行main()中赋值给main2的操作)。
下图是栈在运行过程中的变化。箭头表示栈的增长方向。每个方块代表一帧。开始的时候我们有一个为main()服务的帧,随着调用inner(),我们为inner()增加一个帧。在inner()返回时,我们再次只有main()的帧,直到最后main()返回,其返回地址为空,所以进程结束。
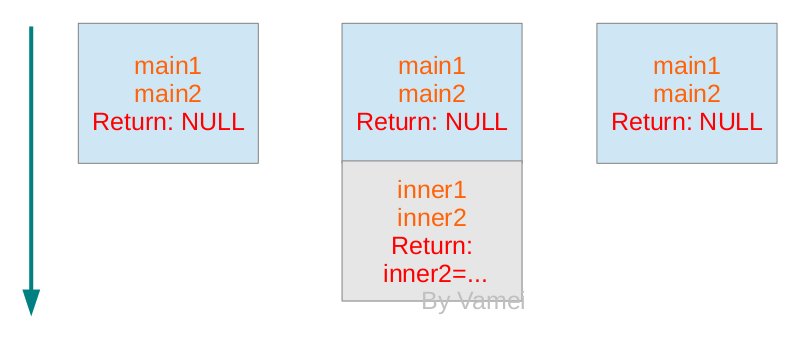
在进程运行的过程中,通过调用和返回函数,控制权不断在函数间转移。进程可以在调用函数的时候,原函数的帧中保存有在我们离开时的状态,并为新的函数开辟所需的帧空间。在调用函数返回时,该函数的帧所占据的空间随着帧的弹出而清空。进程再次回到原函数的帧中保存的状态,并根据返回地址所指向的指令继续执行。上面过程不断继续,栈不断增长或减小,直到main()返回的时候,栈完全清空,进程结束。
当程序中使用malloc的时候,堆(heap)会向上增长,其增长的部分就成为malloc从内存中分配的空间。malloc开辟的空间会一直存在,直到我们用free系统调用来释放,或者进程结束。一个经典的错误是内存泄漏(memory leakage), 就是指我们没有释放不再使用的堆空间,导致堆不断增长,而内存可用空间不断减少。
栈和堆的大小则会随着进程的运行增大或者变小。当栈和堆增长到两者相遇时候,也就是内存空间图中的蓝色区域(unused area)完全消失的时候,再无可用内存。进程会出现栈溢出(stack overflow)的错误,导致进程终止。在现代计算机中,内核一般会为进程分配足够多的蓝色区域,如果清理及时,栈溢出很容易避免。即便如此,内存负荷过大,依然可能出现栈溢出的情况。我们就需要增加物理内存了。
除了上面的信息之外,每个进程还要包括一些进程附加信息,包括PID,PPID,PGID(参考Linux进程基础以及Linux进程关系)等,用来说明进程的身份、进程关系以及其它统计信息。这些信息并不保存在进程的内存空间中。内核会为每个进程在内核自己的空间中分配一个变量(task_struct结构体)以保存上述信息。内核可以通过查看自己空间中的各个进程的附加信息就能知道进程的概况,而不用进入到进程自身的空间 (就好像我们可以通过门牌就可以知道房间的主人是谁一样,而不用打开房门)。每个进程的附加信息中有位置专门用于保存接收到的信号。
现在,我们可以更加深入地了解fork和exec的机制了。当一个程序调用fork的时候,实际上就是将上面的内存空间,包括text, global data, heap和stack,又复制出来一个,构成一个新的进程,并在内核中为改进程创建新的附加信息(比如新的PID,而PPID为原进程的PID)。此后,两个进程分别地继续运行下去。新的进程和原有进程有相同的运行状态(相同的变量值,相同的instructions…)。我们只能通过进程的附加信息来区分两者。
程序调用exec的时候,进程清空自身内存空间的text, global data, heap和stack,并根据新的程序文件重建text, global data, heap和stack(此时heap和stack大小都为0),并开始运行。
转载请注明:宁哥的小站 » Linux下程序如何执行进程