#coding:utf-8
class Apriori():
def __init__(self):
pass
'''
关联分析的目标包括两项:发现频繁项集和发现关联规则
'''
'''
...
fireling
10年前 (2016-10-13) 7237℃
2喜欢
# -*- coding: utf-8 -*-
'''
HMM(隐马尔可夫模型)是用来描述隐含未知参数的统计模型
举一个经典的例子:
一个东京的朋友每天根据天气{下雨,天晴}决定当天的活动{公园散步,购物,清理房间}中的一种
我每天只能在twitter上看到她发...
fireling
10年前 (2016-10-13) 8561℃
2喜欢
#coding:utf-8
import numpy as np
class NaiveBayes():
def __init__(self):
pass
def createVocabList(self, train_x):...
fireling
10年前 (2016-10-13) 6208℃
2喜欢
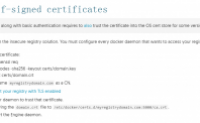
Docker私有仓库一般使用Host:Port形式来代表仓库名称,如果有域名指向这个Host:Port,那么我们可以使用域名来代表仓库名称,这样一方面比较容易记忆,另一方面不会轻易暴露Registry使用的IP和端口。
1. 使用域名登录:
前提:假设域名 myregistry...
fireling
10年前 (2016-08-12) 10857℃
7喜欢
Docker镜像能够以tar包的形式导出和导入,实现程序部署环境的迁移,也能够像github、bitbucket等版本仓库那样将镜像推送到Docker远程仓库上。
Docker仓库分为公有仓库和私有仓库,官方有个仓库叫Docker Hub可以供Docker开发者实现镜像的推送和...
fireling
10年前 (2016-08-11) 9541℃
1喜欢
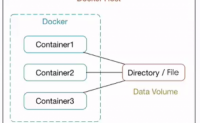
为什么要用数据卷
在Docker容器运行期间,对文件系统的所有修改都会以增量的方式反映在容器使用的联合文件系统中,并不是真正的对只读层数据信息修改。每次运行容器对它的修改,只能适用于当前Docker容器,当删除该容器,或通过该镜像重新启动时,之前的更改将会丢失。这样做并不便于我...
fireling
10年前 (2016-08-11) 9035℃
7喜欢