Yarn负责Hadoop的分布式资源调度,它运行于MapReduce之上,提供了高可用性及高扩展性。在部署Hadoop运行环境也可以启动Yarn来进行资源调度。
下面介绍下,在部署Hadoop伪分布式环境基础上,MapReduce任务如何进行Yarn配置。
- 配置文件修改
这里除了伪分布式需要配置的文件外,还需要进行两个文件的修改,包括mapred-site.xml和yarn-site.xml,其中系统默认不启动Yarn,所以配置文件中存在mapred-site.xml.template,而不是mapred-site.xml,这里需要事先把文件名修改好。
etc/hadoop/mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
etc/hadoop/yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
* 启动ResourceManager进程和NodeManager进程:
sbin/start-yarn.sh
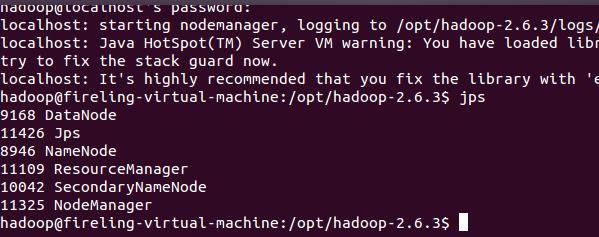
我们可以通过jps命令查看我们启动的进程,如前所述,包括了5个: NameNode、DataNode、SecondaryNameNode、ResourceManager和NodeManager。
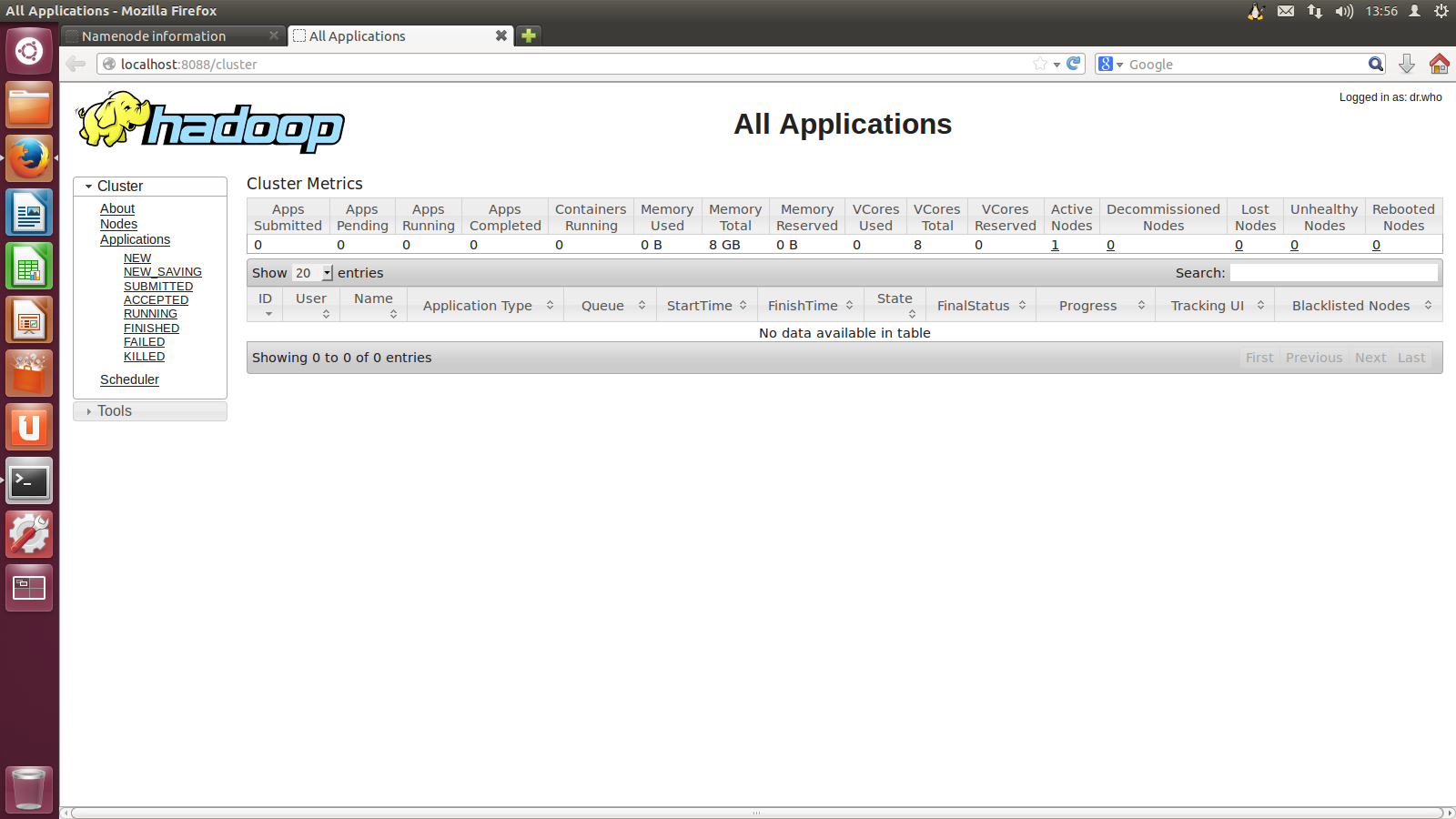
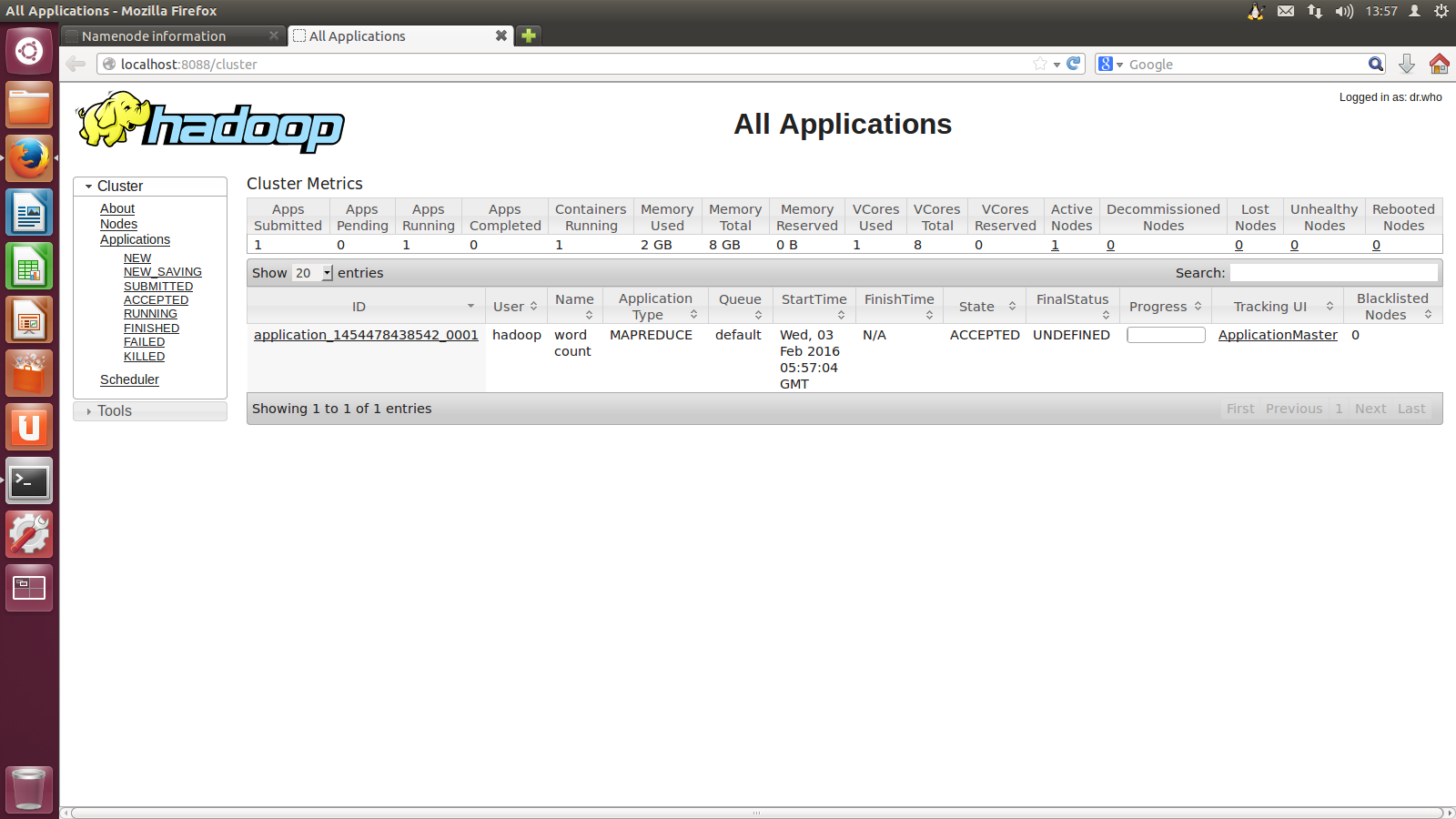
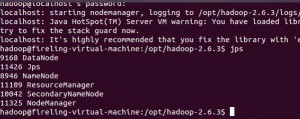 启动ResourceManager进程和NodeManager进程之后,通过访问网址:http://localhost:8088/,可以查看ResourceManager信息。如图所示。
启动ResourceManager进程和NodeManager进程之后,通过访问网址:http://localhost:8088/,可以查看ResourceManager信息。如图所示。
- 执行MapReduce任务:
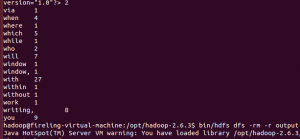
这里我们执行以下官方demo里面的wordcount代码看一下,可以看到,查看ResourceManager信息时,网址http://localhost:8088/中内容的变化。
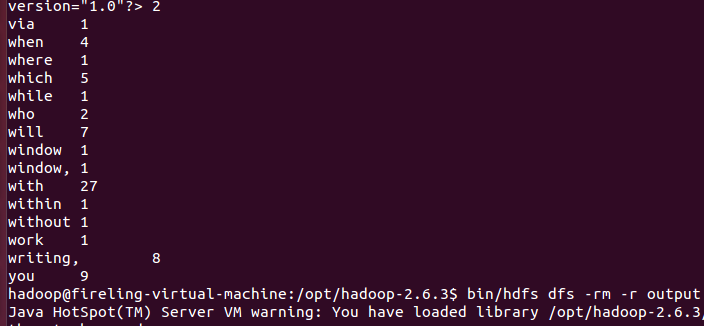
 计算结果如图所示。
计算结果如图所示。
* 关闭ResourceManager进程和NodeManager进程:
sbin/stop-yarn.sh
转载请注明:宁哥的小站 » Hadoop启动Yarn进行资源调度