Hive介绍
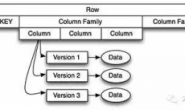
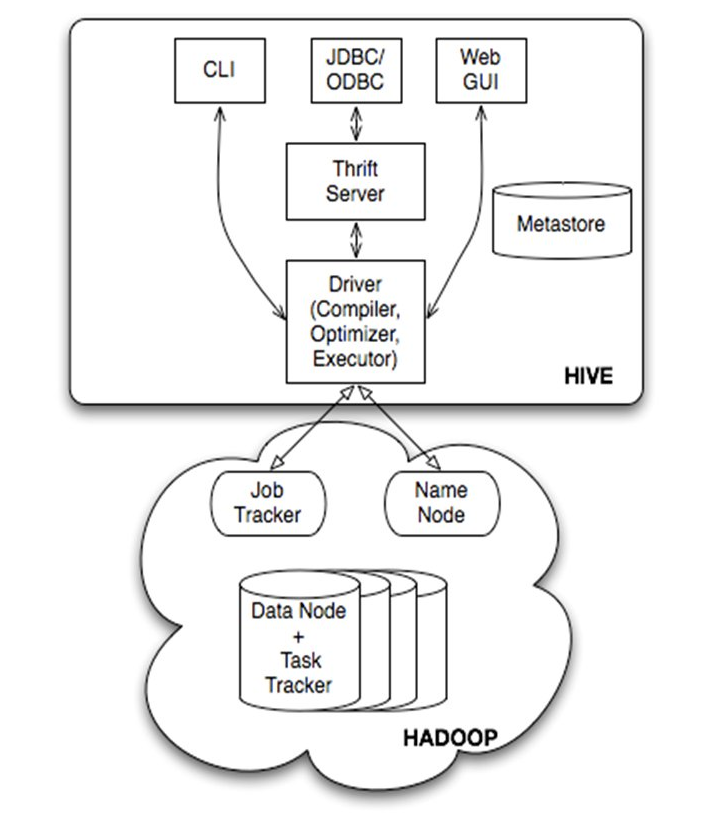
Hive是一个构建于Hadoop顶层的数据仓库。它依赖于HDFS和MapReduce,对HDFS数据提供类似于SQL的操作,可以将SQL语句转换为MapReduce任务进行运行。这样,Hive实现了以SQL查询方式来分析存储在HDFS中的数据,使得不熟悉MapReduce的用户也可以很方便地利用SQL语言查询、汇总、分析数据,也使得开发人员可以把己写的mapper和reducer作为插件来支持Hive做更复杂的数据分析。
Hive中的表结构信息等叫做元数据。虽然Hive不是数据库,但它需要使用数据库存储元数据。默认采用Derby存储,也可以改为MySQL存储。而除去元数据之外的数据,存储在Hadoop的HDFS文件系统中。因此,Hive相比传统的关系数据库,在数据规模上有绝对优势,并且有很强的可扩展性,但是实时性比较差。
Hive环境搭建
Hive会用到HDFS存储数据,因此要先安装Hadoop。
安装Hive
tar -zxvf ./apache-hive*.tar.gz -C /opt
mv /opt/apache-hive* /opt/hive
配置环境变量
export HIVE_HOME=/opt/hive
export PATH=${HIVE_HOME}/bin:$PATH
修改配置文件
在${HIVE_HOME}目录下,主要进行如下几个配置文件的修改:
conf/hive-default.xml
conf/hive-site.xml
conf/hive-env.sh
conf/hive-log4j2.properties
其中,conf/hive-site.xml表示hive的个性化配置,它可以覆盖conf/hive-default.xml中的默认配置。如果想用MySQL作为元数据仓库,典型的配置如下:
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive_metadata?createDatabaseIfNotExist=true&autoReconnect=true&useSSL=false</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>/user/hive/tmp</value>
<description>HDFS root scratch dir for Hive jobs which gets created with write all (733) permission. For each connecting user, an HDFS scratch dir: ${hive.exec.scratchdir}/<username> is created, with ${hive.scratch.dir.permission}.</description>
</property>
<property>
<name>hive.querylog.location</name>
<value>/user/hive/log</value>
<description>Location of Hive run time structured log file</description>
</property>
</configuration>
在HDFS上创建目录
${HADOOP_HOME}/bin/hdfs namenode -format
${HADOOP_HOME}/sbin/start-dfs.sh
${HADOOP_HOME}/bin/hdfs dfs -mkdir -p /user/hive/warehouse
${HADOOP_HOME}/bin/hdfs dfs -mkdir -p /user/hive/tmp
${HADOOP_HOME}/bin/hdfs dfs -mkdir -p /user/hive/log
${HADOOP_HOME}/bin/hdfs dfs -chmod -R 777 /user/hive/warehouse
${HADOOP_HOME}/bin/hdfs dfs -chmod -R 777 /user/hive/tmp
${HADOOP_HOME}/bin/hdfs dfs -chmod -R 777 /user/hive/log
创建MySQL元数据仓库
- 上传MySQL的JDBC库:
cp mysql-connector-java-*-bin.jar ${HIVE_HOME}/lib
- 新建数据库并新建只允许操作该数据库的用户
mysql -u root -p
mysql> create database hive_metadata;
mysql> create user 'hive'@'%' identified by 'hive';
mysql> grant all privileges on hive_metadata.* to 'hive'@'%' identified by 'hive';
mysql> flush privileges;
- 初始化操作
schematool -dbType mysql -initSchema
Hive启动
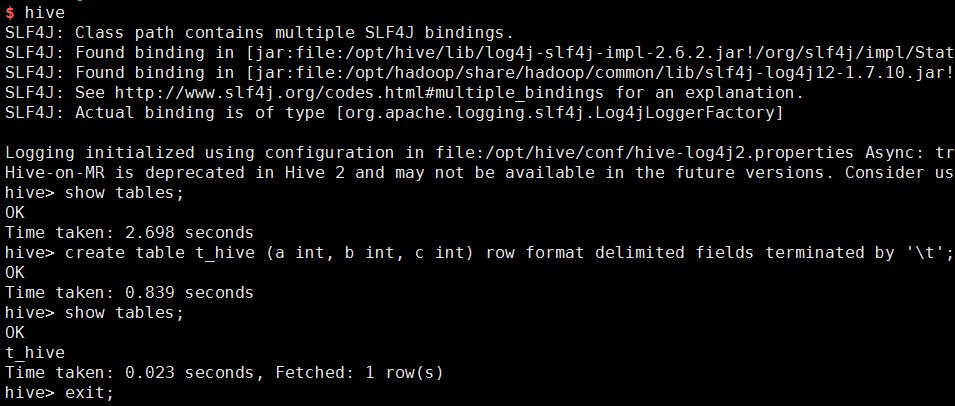
使用Hive交互式Shell进行操作,只需要运行hive命令即可。
在Hive Shell中,可以使用类SQL语句进行表的创建和查询,如:
转载请注明:宁哥的小站 » Hive介绍及环境搭建