以前看过Hadoop及Spark的相关资料,最近又搭建了Hadoop及Spark集群,“反刍”了一下,发现目前的新版本与以前又有了一些变化。Hadoop目前发布了3版本,而Spark已经更新到了2.2版本。本文主要讲一下Spark的搭建及使用。
使用Spark会用到Hadoop的HDFS及YARN,因此在搭建Spark之前需要搭建好Hadoop环境,如果使用的是“Hadoop free”版本,则需要在Spark目录下的conf/spark-env.sh配置文件中指明Hadoop的”classpath”:
### in conf/spark-env.sh ###
# If 'hadoop' binary is on your PATH
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
# With explicit path to 'hadoop' binary
export SPARK_DIST_CLASSPATH=$(/path/to/hadoop/bin/hadoop classpath)
# Passing a Hadoop configuration directory
export SPARK_DIST_CLASSPATH=$(hadoop --config /path/to/configs classpath)
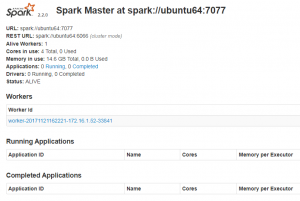
运行Spark目录下的sbin/start-all.sh成功启动Spark后,浏览器访问 http://xxx.xxx.xxx.xx:8080 ,将得到如下界面:
另外,我们可以使用spark-shell命令启动Spark交互式操作界面,Python用户可以使用pyspark命令来启动:
与以前Spark1.x版本相比,Spark2.x版本中加入了一些小变化,最典型的就是将RDDs替换成了Dataset。在1.x版本中,往往先创建一个SparkContext对象,基于这个对象创建一系列RDDs,虽然2.x版本会继续支持RDDs,但Dataset在性能上会更有优势,而且Dataset对于掌握Python/R DataFrame的人来说,更是友好。在创建Spark应用时,往往先启动一个SparkSession会话,基于这个会话创建一系列DataFrame,然后在这个会话中进行相关操作,最后关闭会话。
举个例子:
"""SimpleApp.py"""
from pyspark.sql import SparkSession
spark = SparkSession.builder().appName(appName).master(master).getOrCreate()
logFile = "YOUR_SPARK_HOME/README.md" # Should be some file on your system
logData = spark.read.text(logFile).cache()
numAs = logData.filter(logData.value.contains('a')).count()
numBs = logData.filter(logData.value.contains('b')).count()
print("Lines with a: %i, lines with b: %i" % (numAs, numBs))
spark.stop()
这里,spark就是我们创建的会话,也就是pyspark启动交互式操作界面时默认的起始变量。