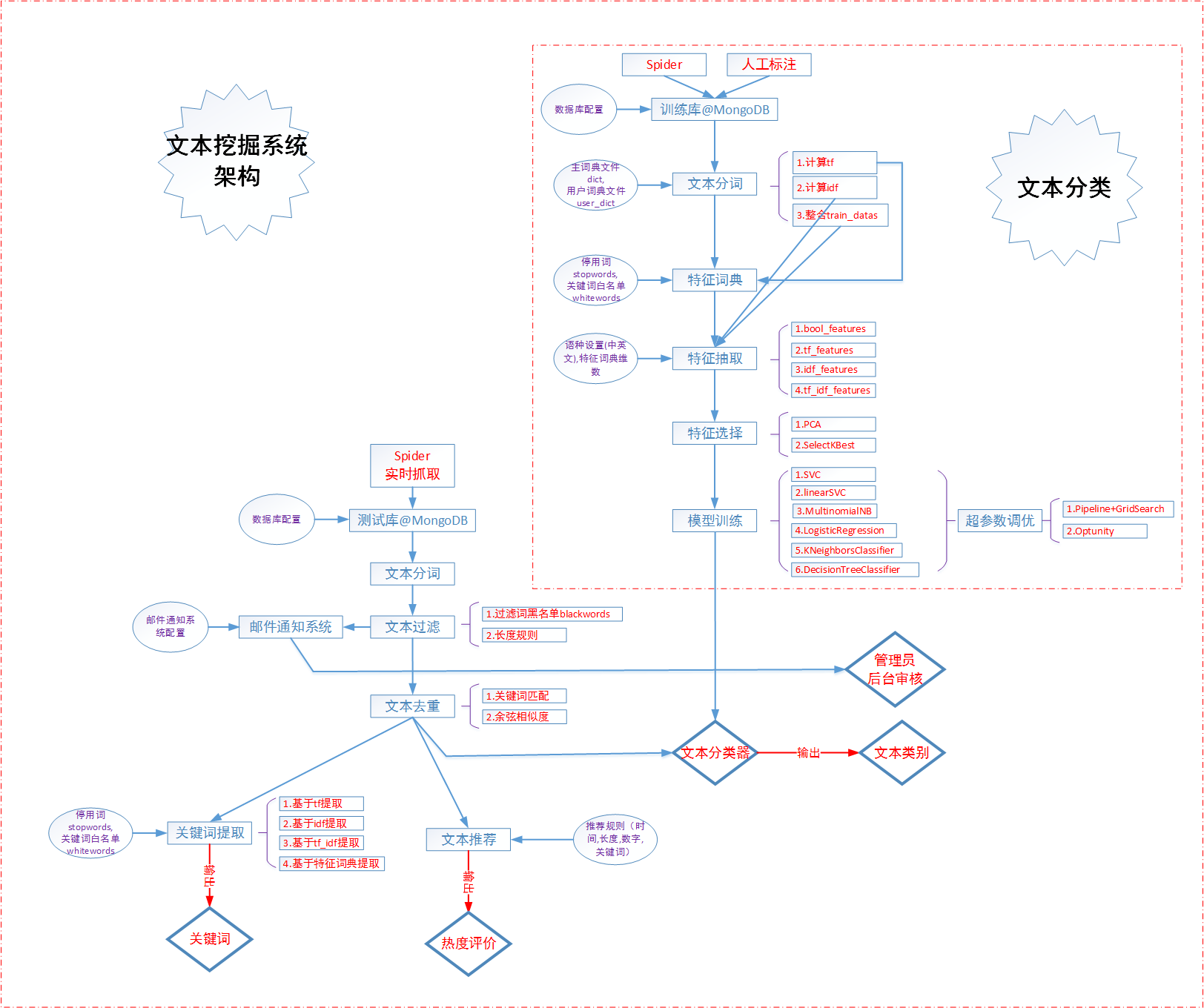
文本挖掘系统 Research of Text Mining System
系统说明
- 集成了文本过滤、去重及邮件实时通知的功能
- 集成了文本关键词提取的功能
- 集成了文本分类即打标签的功能
- 集成了文本推荐即热点评价的功能
- 支持中英文
系统架构图
关于分词
英文分词,采用nltk工具包进行分词
pip install nltk
中文分词,采用jieba工具包进行分词
pip install jieba
jieba分词
dict 主词典文件
user_dict 用户词典文件,即分词白名单
user_dict为分词白名单
- 如果添加的过滤词(包括黑名单和白名单)无法正确被jieba正确分词,则将该需要添加的单词及词频加入到主词典dict文件中或者用户词典user_dict,一行一个(词频也可省略)
关于停用词,黑名单,白名单
stopwords为停用词
- 可以随时添加停用的单词,一行一个
blackwords为过滤词黑名单
- 可以随时添加过滤的单词,一行一个
writewords为关键词白名单
- 可以随时添加关键的单词,一行一个
关于特征词
- 特征词用于分类,用于计算文本特征
- 特征词的选取可以通过该词在训练集中的词频数来确定
- 特征词的维度可以设置
关于配置
config文件:
- 可以进行服务器配置,针对数据库中制订collection的不同字段column
- 可以限定操作数据库条目的数量,默认时间从最近往前推
- 可以选择语言(中文,英文)
- 可以设置分类特征词词典的维度
- 可以设置是否接收邮件通知
- 可以设置版本加速,如果加速分类,此时会将文本特征词和分类模型固定化!因此,如果要测试分类特征词词典的维度、分类器的特征和算法,需要取消加速。
程序文件:
- 可以更改特征词典的生成,通过该词的词频数或者包含该词的文档频率
- 可以更改文本过滤及去重算法
- 可以更改关键词提取算法,可选基于特征词提取、基于Tf提取、基于IDf提取、基于TfIDf提取,可以更改前K个关键词筛选方法
- 可以更改训练集和测试集的特征生成,基于特征词,可选Bool特征、Tf特征、IDf特征(无区分)、TfIDf特征,可以选择进行特征选择或降维
- 可以更改文本分类算法,可选SVC、LinearSVC、MultinomialNB、LogisticRegression、KNeighborsClassifier、DecisionTreeClassifier,可以更改算法调参寻优的方法
- 可以更改文本推荐算法
其他说明
- 更改分词文件dict user_dict lag
需要事先手动删除datas文件夹 - 更改训练集
需要事先手动删除all_words_dict和train_datas - 更改文件stopwords blackwords writewords fea_dict_size
重新运行程序即可
关于环境搭建
Ubuntu下numpy scipy matplotlib的安装
sudo apt-get update
sudo apt-get install git g++ gfortran
sudo apt-get install python-dev python-setuptools python-pip
sudo apt-get install libblas-dev liblapack-dev libatlas-base-dev
export BLAS=/usr/lib/libblas/libblas.so
export LAPACK=/usr/lib/lapack/liblapack.so
export ATLAS=/usr/lib/atlas-base/libatlas.so
sudo apt-get install python-numpy
sudo apt-get install python-scipy
sudo apt-get install python-matplotlib
或
sudo pip numpy
sudo pip scipy
sudo pip matplotlib
sudo pip jieba
sudo pip scikit-learn
sudo pip simplejson
sudo pip pymongo